AI Privacy 360 - Resources
Welcome to the AI Privacy 360 Toolbox
Overview
Many privacy regulations, including GDPR, mandate that organizations abide by certain privacy principles when processing personal information. Why is this relevant to machine learning? Recent studies show that a malicious third party with access to a trained ML model, even without access to the training data itself, can still reveal sensitive, personal information about the people whose data was used to train the model. It is therefore crucial to be able to recognize and protect AI models that may contain personal information.
IBM Research is working on several novel techniques and tools to both assess the privacy risk of AI-based solutions, and to help them adhere to any relevant privacy requirements. We have tools to address different tradeoffs between privacy, accuracy and performance of the resulting models, and for addressing the different stages in the ML lifecycle.
AI on encrypted data - Fully Homomorphic Encryption (FHE) allows data to remain encrypted even during computation. Thus, using FHE we are able implement different analytics and AI solutions over encrypted data.
Differential Privacy - This method allows queries to be executed on sensitive data while preserving the privacy of individuals in the data with its robust mathematical guarantees. Differential privacy relies on random noise to protect individuals’ privacy while preserving accuracy on aggregate statistics and has applications in ML and data analytics more generally.
ML anonymization - This method creates a model-based, tailored anonymization scheme to anonymize training data before using it to train an ML model, enabling to create ML models that no longer contain any personally identifiable information.
Data minimization - This technique helps to reduce the amount and granularity of features used by machine learning algorithms to perform classification or prediction, by either removal (suppression) or generalization.
Privacy risk assessment - We provide ways to assess and quantify the privacy risk of ML models, to enable comparing and choosing between different ML models based not only on accuracy but also on privacy risk.
Privacy in federated learning - Federated Learning is an approach to machine learning in which a group of parties, data owners, work together to train a model collaboratively without actually sharing training data but by exchanging and merging the parameters of locally trained models. For increased privacy this approach can be combined with other techniques such as differential privacy, homomorphic encryption and secure multi-party computation.
Guidance
AI Privacy 360 includes many different assessments and tools, which may result in a daunting problem of making the right selection for a given application. Here we try to provide some guidance.
To start, we suggest following these flowcharts. According to the answers, we list the tools and assessments we find to be most relevant. Note that this is not necessarily a complete list as new attacks and metrics are frequently added to the toolkit.
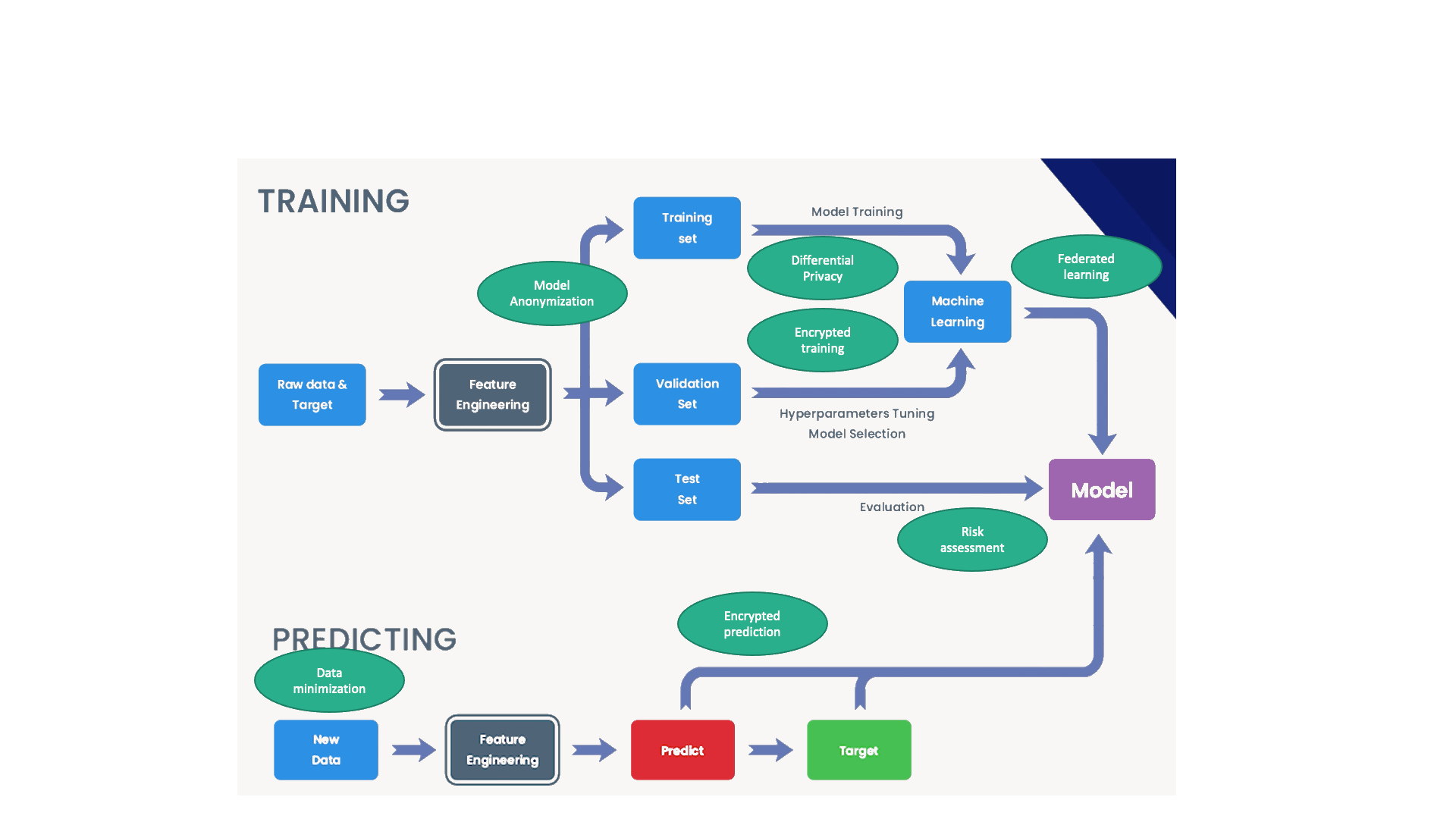
Tool selection flowchart
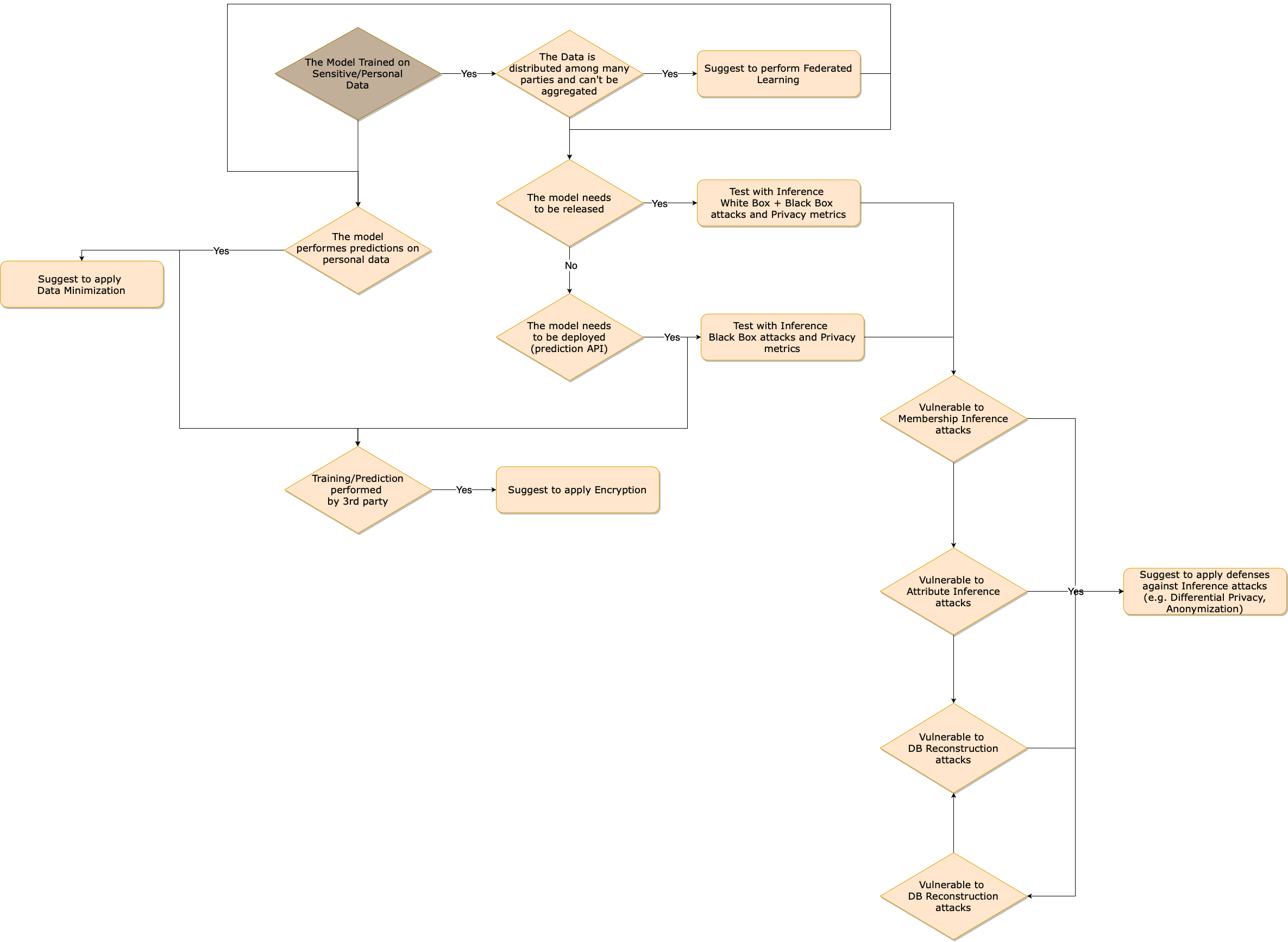
Assessment selection flowchart
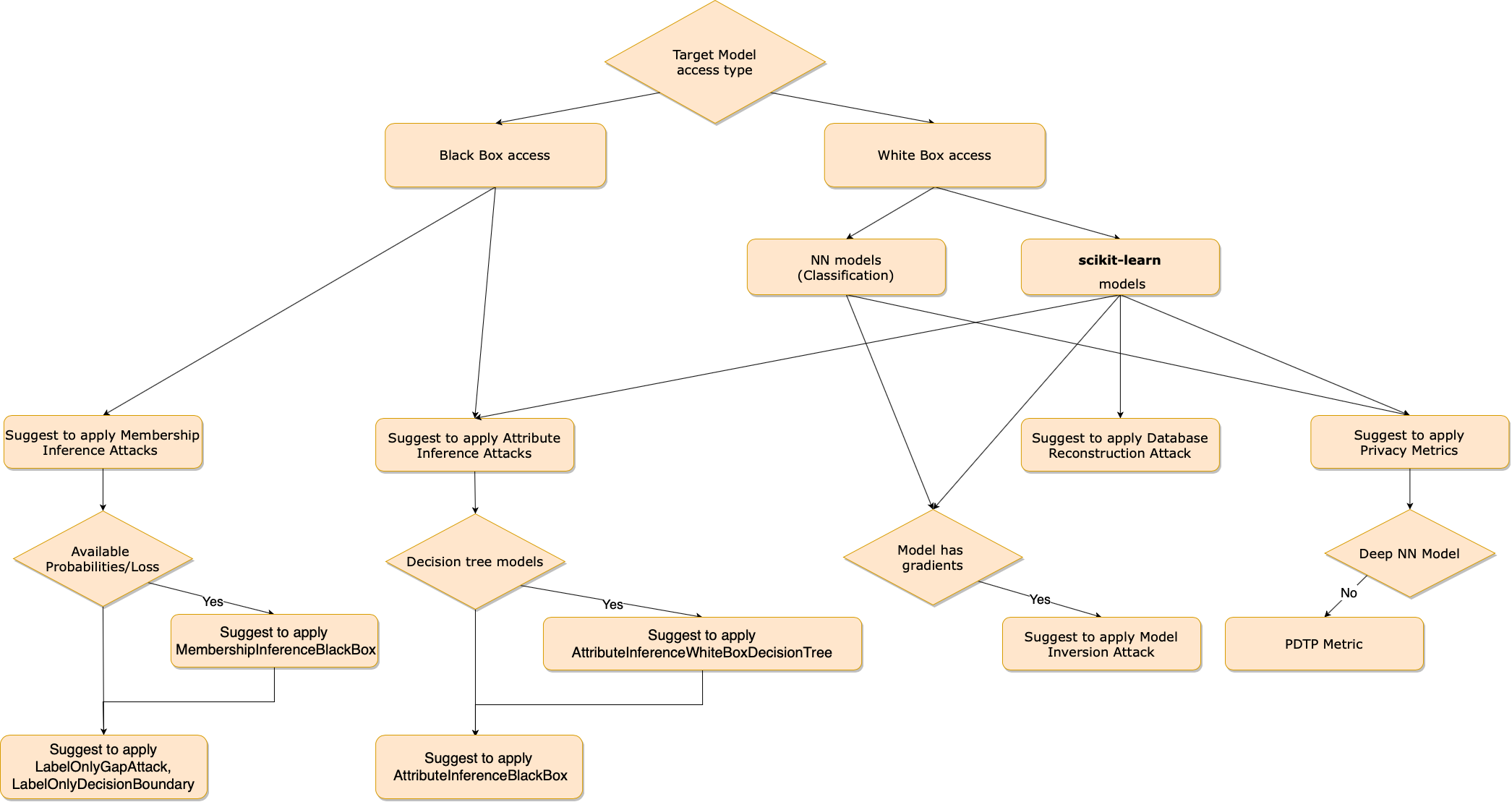
Data for risk assessment
Running the attacks using the model’s actual training and test data is easiest (assuming it’s available) and will give the evaluator a worst-case assessment of the vulnerability of the model. If that data is not available, or to get more realistic results of the risk of an actual attack, train and test data for the attacks should be generated in a different manner. One such option is based on a method called shadow models. To apply this method, the attacker tries to generate their own local version of a model that is similar to, or mimics the behavior of, the target model (for which they do not know the training data). Such a shadow model can be generated by using the same model type and architecture as the target model (if they are known) and training it on a dataset that is assumed to have a similar distribution to the real training data. Such a shadow model can also be generated by first employing an extraction attack as an intermediate step towards the actual inference attack. .
Papers
- Poster: Secure SqueezeNet inference in 4 minutes, Ehud Aharoni, Moran Baruch, Nir Drucker, Gilad Ezov, Eyal Kushnir, Guy Moshkowich, Omri Soceanu, IEEE Symposium on Security and Privacy, 2022
- Applying Artificial Intelligence Privacy Technology in the Healthcare Domain, Abigail Goldsteen, Ariel Farkash, Micha Moffie, Ron Shmelkin, Stud Health Technol Inform, 2022
- An end-to-end framework for privacy risk assessment of AI models, Abigail Goldsteen, Shlomit Shachor, Natalia Raznikov, 15th ACM International Conference on Systems and Storage (SYSTOR), 2022
- Secure Random Sampling in Differential Privacy, Naoise Holohan, Stefano Braghin, ESORICS, 2021
- Accountable Federated Machine Learning in Government: Engineering and Management Insights, Dian Balta, Mahdi Sellami, Peter Kuhn, Ulrich Schöpp, Matthias Buchinger, Nathalie Baracaldo, Ali Anwar, Heiko Ludwig, Mathieu Sinn, Mark Purcell, Bashar Altakrouri, EGOV2021 – IFIP EGOV-CeDEM-EPART, Electronic Participation, 2021
- Anonymizing Machine Learning Models, Abigail Goldsteen, Gilad Ezov, Ron Shmelkin, Micha Moffie, Ariel Farkash, International Workshop on Data Privacy Management, ESORICS, 2021
- Data Minimization for GDPR Compliance in Machine Learning Models, Abigail Goldsteen, Gilad Ezov, Ron Shmelkin, Micha Moffie, Ariel Farkash, AI Ethics, 2021
- Reducing Risk of Model Inversion Using Privacy-Guided Training, Abigail Goldsteen, Gilad Ezov, Ariel Farkash, arXiv preprint arXiv:2006.15877, 2020
- Diffprivlib: the IBM differential privacy library, Holohan, Naoise, Stefano Braghin, Pól Mac Aonghusa, and Killian Levacher. arXiv preprint arXiv:1907.02444 (2019)
- Tile Tensors: A versatile data structure with descriptive shapes for homomorphic encryption, Aharoni E, Adir A, Baruch M, Ezov G, Farkash A, Greenberg L, Masalha R, Murik D, Soceanu O. Tile Tensors: A versatile data structure with descriptive shapes for homomorphic encryption, arXiv preprint arXiv:2011.01805. 2020 Nov 3
- Efficient Encrypted Inference on Ensembles of Decision Trees, Sarpatwar K, Nandakumar K, Ratha N, Rayfield J, Shanmugam K, Pankanti S, Vaculin R. arXiv preprint arXiv:2103.03411. 2021 Mar 5
- Homomorphic training of 30,000 logistic regression models, Bergamaschi F, Halevi S, Halevi TT, Hunt H. In International Conference on Applied Cryptography and Network Security 2019 Jun 5 (pp. 592-611). Springer, 2019
- HybridAlpha: An Efficient Approach for Privacy-Preserving Federated Learning, Runhua Xu, Nathalie Baracaldo, Yi Zhou, Ali Anwar and Heiko Ludwig, 12th ACM Workshop on Artificial Intelligence and Security (AISec 2019), Nov, 2019, arXiv, Dec, 2019
- A Hybrid Approach to Privacy-Preserving Federated Learning, Stacy Truex, Nathalie Baracaldo, Ali Anwar, Thomas Steinke, Heiko Ludwig, Rui Zhang, and Yi Zhou, arXiv, Dec, 2018, AiSec 2019
- A Syntactic Approach for Privacy-Preserving Federated Learning, O. Choudhury, A. Gkoulalas-Divanis, T. Salonidis, I. Sylla, Y. Park, G. Hsu, A. Das, European Conference on Artificial Intelligence (ECAI)
- Secure Model Fusion for Distributed Learning Using Partial Homomorphic Encryption, Changchang Liu, Supriyo Chakraborty, Dinesh Verma, SpringerLink, Apr, 2019
- Analyzing Federated Learning Through an Adversarial Lens, Arjun Nitin Bhagoji, Supriyo Chakraborty, Prateek Mittal, Seraphin Calo, ICML 2019, Nov, 2018, arXiv, Nov, 2018
- Towards Federated Graph Learning for Collaborative Financial Crimes Detection, Toyotaro Suzumura, Yi Zhou, Nathalie Baracaldo, Guangann Ye, Keith Houck, Ryo Kawahara, Ali Anwar, Lucia Larise Stavarache, Yuji Watanabe, Pablo Loyola, Daniel Klyashtorny, Heiko Ludwig, and Kumar Bhaskaran, NeurIPS 2019 Workshop on Robust AI in Financial Services, Dec, 2019, arXiv, Sep, 2019
- Differential Privacy-enabled Federated Learning for Sensitive Health Data, O. Choudhury, A. Gkoulalas-Divanis, T. Salonidis, I. Sylla, Y. Park, G. Hsu, A. Das, NeurIPS ML4H (Machine Learning for Health), 2019, Dec, 2019
- Predicting Adverse Drug Reactions on Distributed Health Data using Federated Learning, O. Choudhury, Y. Park, T. Salonidis, A. Gkoulalas-Divanis, I. Sylla, A. Das, American Medical Informatics Association (AMIA), 2019
- Curse or Redemption? How Data Heterogeneity Affects the Robustness of Federated Learning, Syed Zawad, Ahsan Ali, Pin-Yu Chen, Ali Anwar, Yi Zhou, Nathalie Baracaldo, Yuan Tian, Feng Yan, arXiv, Feb, 2021
- Sharing Models or Coresets: A Study based on Membership Inference Attack, H. Lu, C. Liu, T. He, S. Wang, K. S. Chan, FL-ICML Workshop 2020, arXiv, Jul, 2020
- FedV: Privacy-Preserving Federated Learning over Vertically Partitioned Data, Runhua Xu, Nathalie Baracaldo, Yi Zhou, Ali Anwar, James Joshi, Heiko Ludwig, arXiv, Mar, 2021
Attacks and Metrics
Black-box attack - assumes “black-box access” to the trained model. This typically means that the attacker is assumed to have knowledge of either the confidence or probability vector for each possible class output from the model, or in some cases only the top-N probabilities or even the single predicted value/class. This is typically the case when using MLaaS (machine-learning-as-a-service) or when deploying ML models to make decisions in externally used products or websites.
White-box attack - assumes access to the internals of the model, including the model’s architecture, parameters and weights. This is typically the case when the ML model itself is published or shared with third parties.
Membership inference - an attack where, given a trained model and a data sample, one can deduce whether or not that sample was part of the model’s training. This can be considered a privacy violation if the mere participation in training a model may reveal sensitive information, such as in the case of disease progression prediction.
Attribute inference - an attack where certain sensitive features may be inferred about individuals who participated in training a model. Given a trained model and knowledge about some of the features of a specific person, it may be possible to deduce the value of additional, unknown features of that person.
Model inversion - an attack that aims to reconstruct representative feature values of the training data by inverting a trained ML model. For example, it may be possible to reconstruct what the average sample for a given class looks like. This can be considered a privacy violation if a class represents a certain person or group of people, such as in facial recognition models.
DB reconstruction - an attack where, given a trained model and all training samples except one, it is possible to reconstruct the values of the missing record.
Membership leakage metrics - a class of metrics that measure the amount of information about a single sample (or a complete dataset) that is leaked by a model. It can be computed for example by comparing the characteristics (e.g., weights) of the model with those of models trained without that sample, or by measuring the mutual information between the training data and the output of the model. The higher the membership leakage of a model, the higher the privacy risk.
Privacy Risk Factors
Additional factors or characteristics of machine learning models that have been found to be correlated with higher privacy risk include:
Overfitting - measured by the difference between training accuracy (accuracy of the model as measured on the training set) and test accuracy (accuracy of the model as measured on the hold-out set). The higher this difference, the higher the privacy risk, since it is easier to distinguish between training samples (members) and non-training samples (non-members) based on the model’s behavior.
Training set size - the number of samples in the training set. The smaller the set, the higher the privacy risk, since the model can better “memorize” the samples. In addition, the lower the amount ofdata in the training set associated with a givenclass, the easier it is toattackthat class.
Number of features - the higher the number of features the higherthe privacy risk, since thisagain enables better memorization of the training data and may lead to higher overfitting.
Number of classes - the higher the number of classes the higher the privacy risk, since the model needs to extract more distinctive features from the data to be able to classify inputs with high accuracy. In other words, models with more output classes need to remember more about their training data, thus they leak more information.
Sensitivity of model - sensitivity analysis describes the severity of change of the model’s output related to the change of a given input value. This is also sometimes called ‘model stability’. The higher the sensitivity of a model, the higher the privacy risk.
Feature influence - the higher the influence (or importance) of a sensitive feature on a model, the higher the risk of attribute inversion for that feature.
Updates to existing model - when releasing several versions of the same model, inference risk increases for the samples introduced between updates.
Data augmentations - data augmentation transformations such as shift, flip, rotation, etc. tend to increase the inference risk.
Defenses
Fully Homomorphic encryption (FHE) - a mathematical concept that allows computations to perform calculations on encrypted data without decrypting it. Researcher Craig Gentry compared it to “one of those boxes with the gloves that are used to handle toxic chemicals… All the manipulation happens inside the box, and the chemicals are never exposed to the outside world".
Differential privacy - a method for limiting the disclosure of private information of records whose information is in a database. The idea is that if the effect of making an arbitrary single substitution in the database is small enough, the query result cannot be used to infer much about any single individual, and therefore provides privacy. An algorithm is considered differentially private if an observer seeing its output cannot tell if a particular individual's information was used in the computation. ε-differential privacy provides a privacy parameter (called ‘privacy budget’).
k-anonymity - a method to reduce the likelihood of any single person being identified when a dataset is linked with other, external data sources. The approach is based on generalizing attributes, and possibly deleting records, until each record becomes indistinguishable from at least 𝑘 − 1 other records. k is the privacy parameter that determines how many records will be indistinguishable from each other in the dataset. The higher the value of k, the higher the privacy protection. The quasi-identifiers are the features that can be used to re-identify individuals, either on their own or in combination with additional data.
ℓ-diversity - an extension to basic k-anonymity that tries to better protect sensitive attributes in the data. A sensitive attribute is an attribute whose value for any particular individual must be kept secret from people who have no direct access to the original data. The ℓ-diversity model adds the promotion of intra-group diversity for sensitive values in the anonymization mechanism. A table is said to have ℓ-diversity if for each equivalence class there are at least ℓ “well-represented” values for the sensitive attribute. If ℓ-diversity was applied, the ℓ value is also reported. A higher ℓ means better privacy. k-anonymity and its extensions are applied to the training data prior to training the model.
t-closeness - a further refinement of ℓ-diversity that takes into account the distribution of data values for the sensitive attribute. A table is said to have t-closeness if for each equivalence class the distance between the distribution of a sensitive attribute in this class and the distribution of the attribute in the whole table is no more than a threshold t. If t-closeness was applied, the t value is also reported. A lower t means better privacy.
Model guided anonymization - a method for creating a model-based, tailored anonymization scheme to anonymize training data before using it to train an ML model. This enables creating ML models that no longer contain any personally identifiable information. This method is based on the k-anonymity construct, but it receives a trained ML model as input and uses the model’s predictions on the data to guide the creation of the groups of k (or more) similar samples that will be anonymized together to the same generalized group.
Data minimization for ML - a method for performing data minimization for ML models that can reduce the amount and granularity of input data used to perform classification or prediction by machine learning models. The method determines for each input feature whether it is required or not, and if it is required, the level of detail (granularity) of that feature that is required by the model to make accurate predictions. Then, any newly collected data can be minimized such that it satisfies the data minimization requirement.
Regularization - a technique designed to prevent overfitting and allow for better generalized models. There are many types of regularization methods, including data augmentation, dropout, early stopping, ensembling and adding a regularization term to the loss function of the model. Common regularization terms include L1 and L2. This type of regularization has a parameter λ that determines the weight of the regularization term (the higher the λ the more generalized the model is).
Related Trusted AI Technologies
Fairness
Machine learning models are increasingly used to inform high stakes decisions about people. Although machine learning, by its very nature, is always a form of statistical discrimination, the discrimination becomes objectionable when it places certain privileged groups at systematic advantage and certain unprivileged groups at systematic disadvantage. The AI Fairness 360 toolkit includes a comprehensive set of metrics for datasets and models to test for biases, explanations for these metrics, and algorithms to mitigate bias in datasets and models. The AI Fairness 360 interactive demo provides a gentle introduction to the concepts and capabilities of the toolkit. The package includes tutorials and notebooks for a deeper, data scientist-oriented introduction.
To learn more about this toolkit, visit IBM Research AI Fairness 360.
Explainability
Black box machine learning models are achieving impressive accuracy on various tasks. However, as machine learning is increasingly used to inform high stakes decisions, explainability of the models is becoming essential. The AI Explainability 360 toolkit includes algorithms that span the different dimensions of ways of explaining along with proxy explainability metrics. The AI Explainability 360 interactive demo provides a gentle introduction to the concepts and capabilities of the toolkit. The package includes tutorials and notebooks for a deeper, data scientist-oriented introduction.
To learn more about this toolkit, visit IBM Research AI Explainability 360.
Adversarial Robustness
The number of reports of real-world exploitations using adversarial attacks against AI is growing, highlighting the importance of understanding, improving, and monitoring the adversarial robustness of AI models. The Adversarial Robustness 360 Toolkit provides a comprehensive and growing set of tools to systematically assess and improve the robustness of AI models against adversarial attacks, including evasion and poisoning.
To learn more about this toolkit, visit IBM Research Adversarial Robustness 360.
Uncertainty Quantification
Uncertainty quantification gives AI the ability to express that it is unsure, adding critical transparency for the safe deployment and use of AI. Uncertainty Quantification 360 is an extensible open-source toolkit with a Python package that provides data science practitioners and developers access to state-of-the-art algorithms, to streamline the process of estimating, evaluating, improving, and communicating uncertainty of AI and machine learning models.
To learn more about this toolkit, visit IBM Research Uncertainty Quantification 360.
Transparency and Governance
There is an increasing call for AI transparency and governance. The FactSheets project's goal is to foster trust in AI by increasing understanding and governance of how AI was created and deployed. The FactSheet 360 website includes many example FactSheets for publically available models, a methodology for creating useful FactSheet templates, an illustration of how FactSheets can be used for AI governance, and various resources, such as over 24 hours of video lectures.
To learn more about this project, visit IBM Research AI FactSheets 360.